www.wimb.net - HTML Link Grabber




The program works in two "passes". In the first pass the HTML file is read and modified into a file with lines starting with "<a" and ending with "a>". In the second pass the exact URL and the name of the link is searched for.
The program does not work direct on Internet. All the lines of the file are read and as soon as the "<a" is found; the characters are saved in a buffer. All characters before this "<a" are deleted from the line. During the fill of the buffer the program looks for the "a>" closure tag. When the closure tag is found the buffer is added to the memo and made empty for the next line.
The next line of the HTML file is added to the rest of the previous line. This is done to avoid problems when a link is put on multiple lines, or when multiple links are put on one single line.

1e pass...
Here the screen after the first pass.
When the whole file is done, all lines are visible in the memo. The status bar shows a line number counter. As extra the memo is automatically saved in a file "urlsave.txt". At the end of each line a <br /> tag is added.
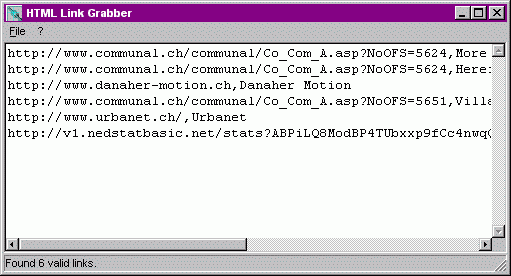
2e pass...
Here the screen after the second pass.
The program has one switchable option; it can sort the lines in the memo. The lines from the previous saved "urlsave.txt" are now being processed. The first step is to look for "HREF". When found, the URL is extracted. Next the program looks for an "IMG" tag. If found, the text of the "ALT" tag is used for the URL name. If there is no "ALT" tag then the name of the picture is used for this. In a line without an "IMG", the text between the "<" and ">" is taken. Between the URL and the name field a comma is placed as separator.
To make the output of the program usable, it can be saved as a CSV file. This is a simple ASCII file with comma-separated fields. In this program there are only two fields, the URL and the name of the URL.
The CSV file can be imported by a database program for further processing, like checking for double URL's. When it is all good, it can be exported to a program to make an HTML page.



Updated 2007 Oct. 09